Почему один и тот же ChatGPT даёт разные ответы — в 6 раз?
Представьте смартфон. Внутри мощный чип Apple A18, но качество камеры зависит от стекла, матрицы, программы обработки. То же самое с LLM.
Исследователи из Стэнфорда заметили простую вещь: если вы меняете только harness (код вокруг модели) — без изменения самой модели — результаты меняются в 6 раз.
Для маркетолога, дизайнера или фронтендера это означает: качество ИИ-приложения зависит не только от того, какую модель вы взяли, но и от того, как вы её «упаковали».
Если код вокруг модели важнее модели — кто его пишет?
Сейчас этим занимаются люди. Разработчики читают ошибки, крутят настройки вручную, пробуют разные варианты. Это медленно и дорого.
Авторы статьи спросили: а что если этот процесс автоматизировать? Что если ИИ-агент может писать и оптимизировать код для другого ИИ?
Так родилась Meta-Harness — система, которая перебирает варианты harness автоматически, как опытный инженер-оптимизатор.
Главное открытие: информация важнее объёма
Большинство существующих оптимизаторов текста (OPRO, TextGrad, AlphaEvolve) работают по принципу: возьми последний результат, сожми в краткое резюме, попроси модель улучшить.
Но это не работает для harness'а. Почему?
Потому что harness — это не просто текст. Это целая система с памятью, порядком операций, логикой извлечения данных. Если что-то сломалось на 10-м шаге, нужно понимать что произошло на шагах 1–9. Если сжать эту информацию в три предложения — теряется диагностика.
Meta-Harness делает по-другому. Она запоминает всю историю попыток — код, результаты, трассировки ошибок — и хранит на диске обычными файлами. Когда нужно придумать следующий вариант, система «читает» эту историю, как инженер, изучающий логи предыдущих проектов.
Это разница между «улучши это» и «вот тебе полное досье со всеми попытками — посмотри, что я уже пробовал».
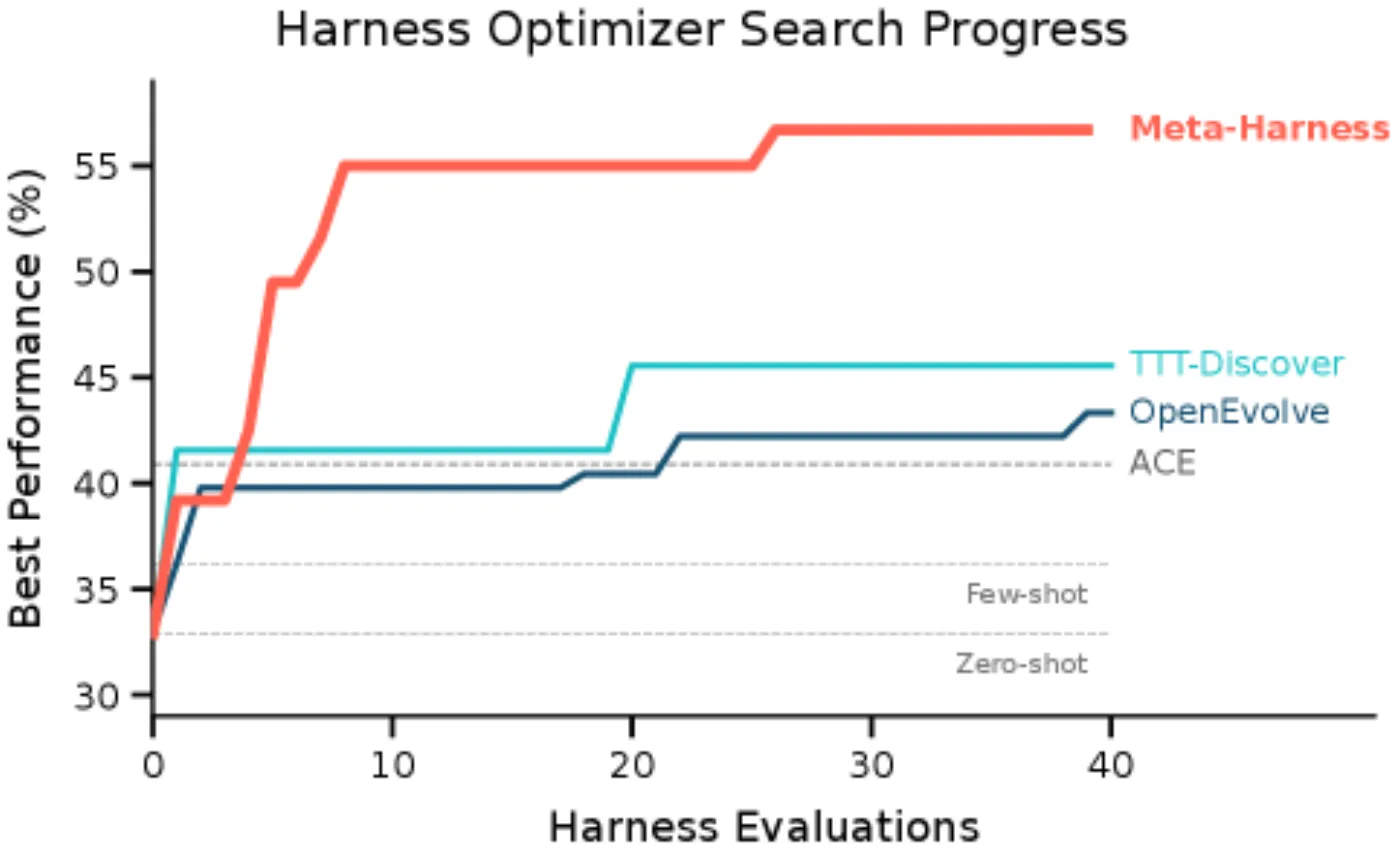
Эксперимент №1: классификация текстов в реальном времени
Задача: система читает входящие сообщения и классифицирует их (спам / не спам, тональность, тип запроса). При этом контекстное окно ограничено — нельзя держать в памяти всё подряд.
Что проверили:
- Старые методы (TTT-Discover, OpenEvolve) — требуют много контекста
- Ручной baseline ACE — лучше, но не идеально
- Meta-Harness — на 7,7 пункта выше ACE и при этом использует контекст в 4 раза меньше
Система перебрала варианты и нашла оптимальный способ хранить и показывать информацию, не перегружая модель. На 9 других OOD-датасетах найденная стратегия тоже сработала — это значит метод не overfits под один тест.
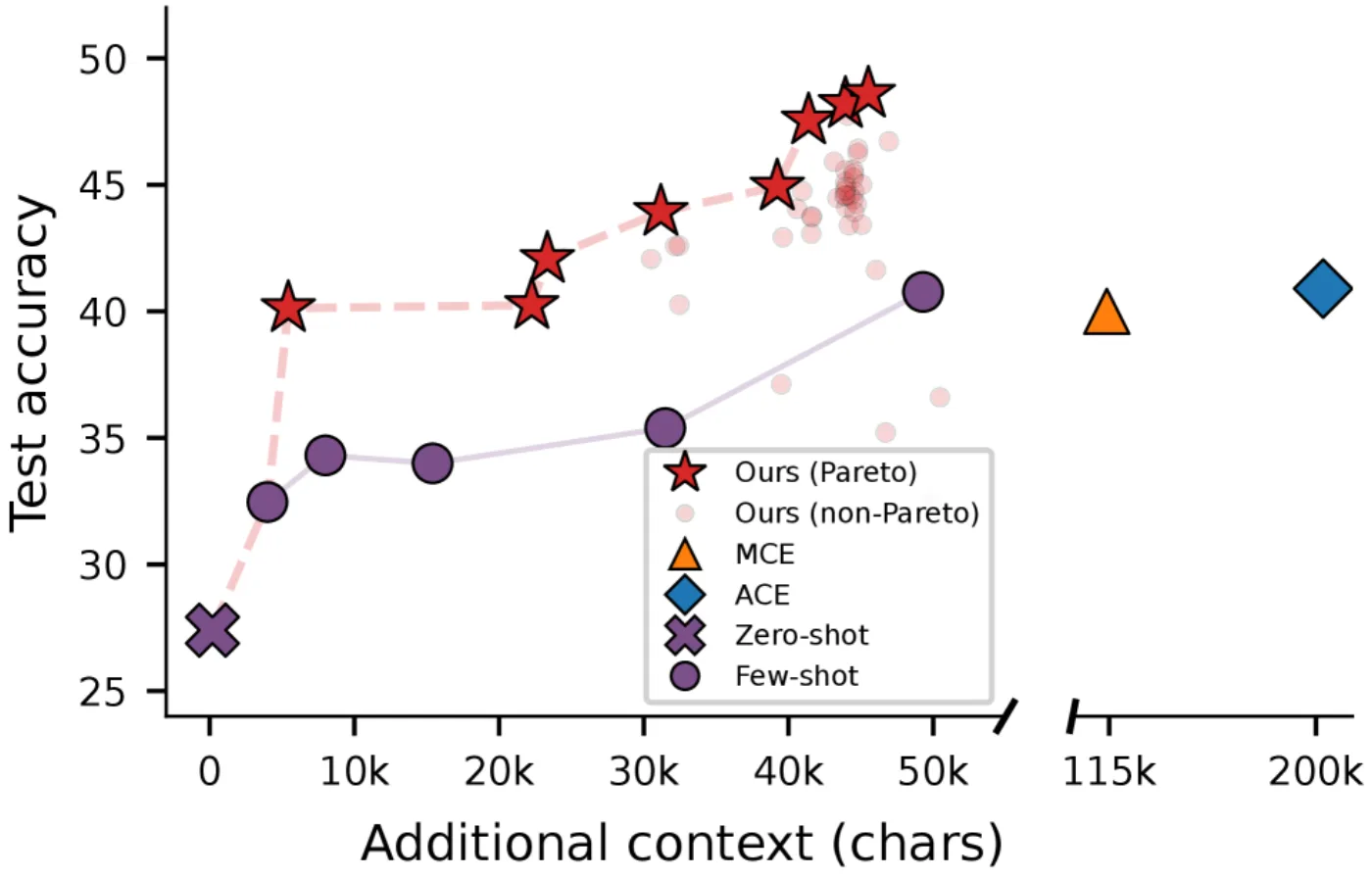
Эксперимент №2: математика олимпиадного уровня
Задача: решить 200 задач, достойных IMO (Международной математической олимпиады). Это самые сложные математические задачи для LLM.
Идея: дать модели возможность искать похожие задачи и их решения в большой базе из 500 000 решённых примеров. Эта техника называется RAG. Но какие примеры искать? В каком порядке? В какой форме показывать?
Meta-Harness автоматически открыла правильную retrieval-политику:
- +4,7 пункта точности в среднем
- Работает одинаково на 5 разных моделях (GPT-5.4-nano, GPT-5.4-mini, Gemini-3-Flash и др.) — это значит политика переносится, не вшита под одну модель
- Найдена за несколько десятков попыток вместо месяцев ручного перебора
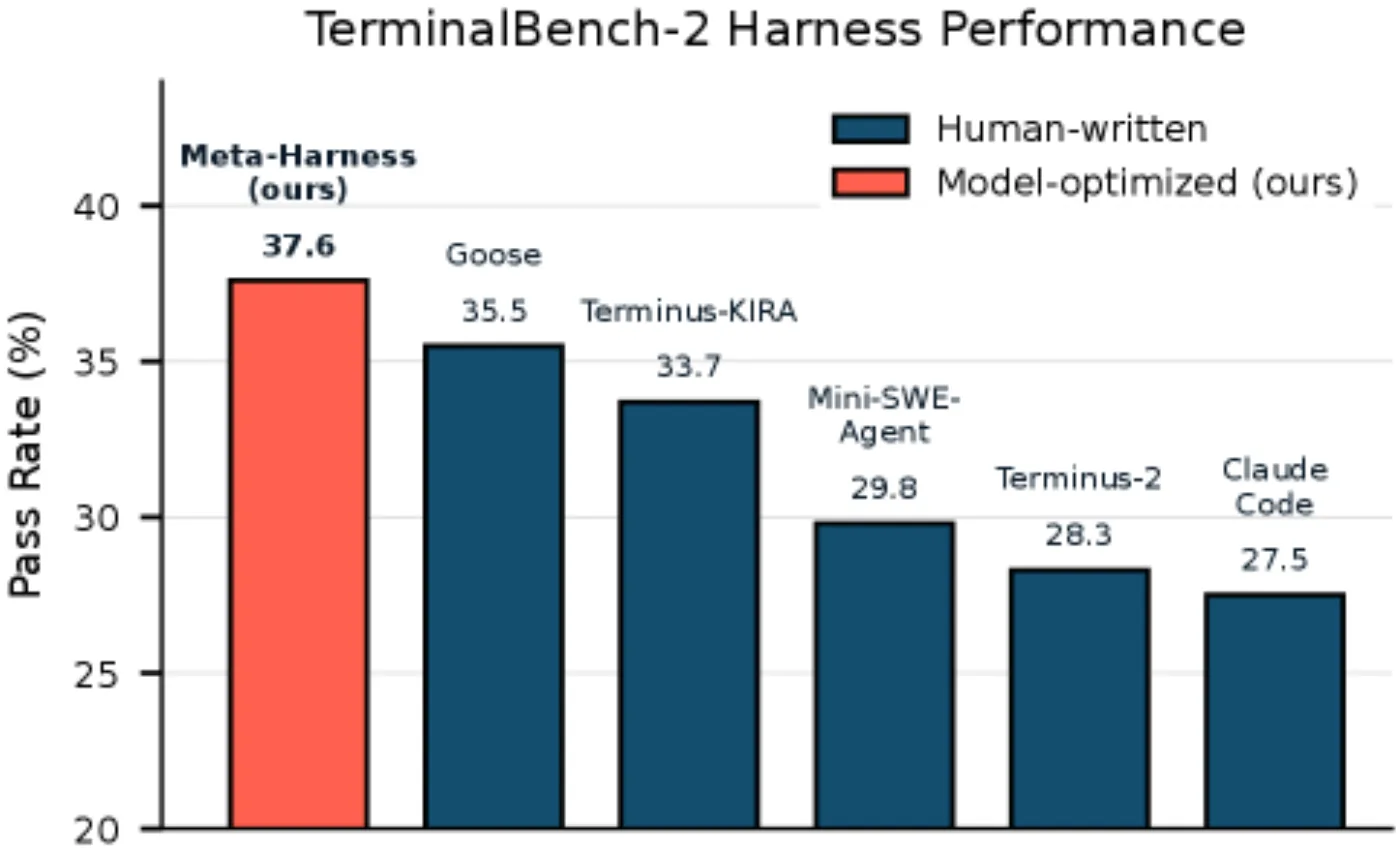
Эксперимент №3: агенты-программисты
Задача: написать код для сложных задач из бенчмарка TerminalBench-2. ИИ-агент запускает команды в терминале, читает ошибки, переписывает код — как настоящий джуниор-разработчик.
Что оптимизировали: как показывать ошибки агенту, сколько истории помнить, какие инструменты предоставлять, как структурировать prompt.
Результат: на Claude Opus 4.6 — №2 место на лидерборде (76,4% pass rate). На Claude Haiku 4.5 — №1 среди всех агентов (37,6%). То есть Meta-Harness нашла harness, который автоматически лучше любого ручного решения, написанного людьми.
Как это работает изнутри?
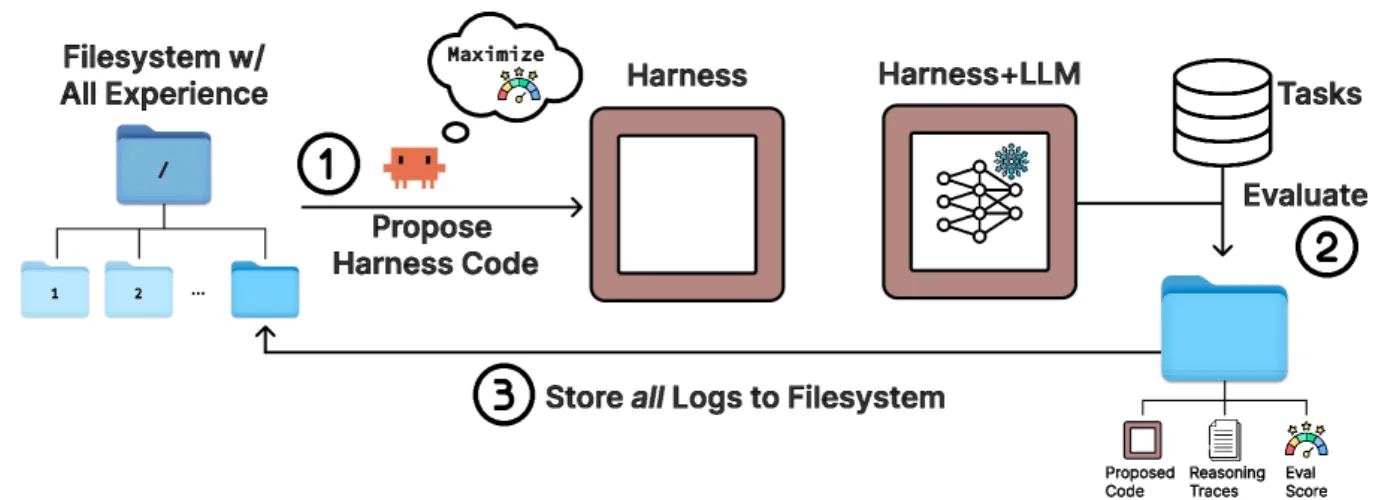
Шаг 1. Хранилище всей истории
Когда система пробует новый harness, она сохраняет:
- Исходный код самого harness'а
- Оценки (точность, скорость, размер контекста)
- Трассировки выполнения (что произошло в каждый момент)
Всё это лежит как обычные файлы на диске. Никакой магии.
Шаг 2. Умный агент-предложитель
Затем включается ИИ-агент, который:
- Читает историю — весь предыдущий код, все результаты, все ошибки
- Анализирует причины неудач — «почему это не сработало?»
- Предлагает конкретное изменение с объяснением
Например, агент может рассуждать так:
«На сложных задачах модель теряется в контексте. Предлагаю добавить снимок окружения перед первым вызовом модели. Это сэкономит 3–5 попыток на задачах с зависимостями, без риска сломать уже работающее».
Шаг 3. Проверка и повтор
Система запускает новый harness, оценивает, сохраняет результат — и цикл повторяется.
Ключевой момент: агент видит всю предыдущую работу, а не только «лучший результат». Это позволяет ему учиться на ошибках по-человечески.
Почему это по-другому, чем «улучши промпт»?
Современные prompt-оптимизаторы работают примерно так:
Возьми лучший результат → сожми обратную связь → попроси модель улучшитьЭто масштабируется, но теряет диагностику. Для RAG и MCP-интеграций этого недостаточно.
Meta-Harness работает так:
Сохраняй ВСЮ историю → дай агенту читать код + результаты + трассировки →
попроси анализировать ПРИЧИНЫ (не оценки) → предложи целевое изменениеРезультат: агент рассуждает причинно-следственно. «Это не сработало потому что…» — вместо «это плохо, сделай лучше».
Кому это нужно на практике?
Для AI-разработчиков
- Автоматически оптимизировать процессы запуска и отладки агента
- Настраивать scaffolding под конкретный проект
- Улучшать способ, как агент видит ошибки
Для LLM-приложений (чат-боты, AI-консультанты, поиск)
- Автоматически настраивать retrieval-политику для RAG
- Оптимизировать форму, в которой информация попадает в модель
- Управлять контекстным окном без потери качества
Для бизнеса
- Вместо нанимать специалиста по harness engineering на полную ставку — запустить Meta-Harness
- Снижение контекстного окна в 4 раза = экономия на API-токенах
- Улучшение точности за несколько часов автоматизации, а не недель ручной работы
Интересные находки из экспериментов
1. Композиция независимых улучшений
Агент заметил, что разные исправления не мешают друг другу. Начал комбинировать: «Улучшение A решило проблему X, улучшение B решило проблему Y. Давай применим оба». Результат — лучше, чем каждое по отдельности.
2. Трансфер между экспериментами
В одном эксперименте система нашла стратегию (+18 пунктов), которую в другом запуске не удалось полностью реализовать. На 10-й итерации агент сам вспомнил: «Это было выигрышной стратегией раньше — попробую ещё раз с новой реализацией».
3. Отказ от опасных гипотез
На 5 итерациях подряд агент пробовал трогать промпты и логику confirmation flow'а. Каждый раз — регрессия. На итерации 7 он принял решение: «Перестаю трогать это. Буду только добавлять информацию». И это сработало.
Это не случайный поиск — это каузальное рассуждение.
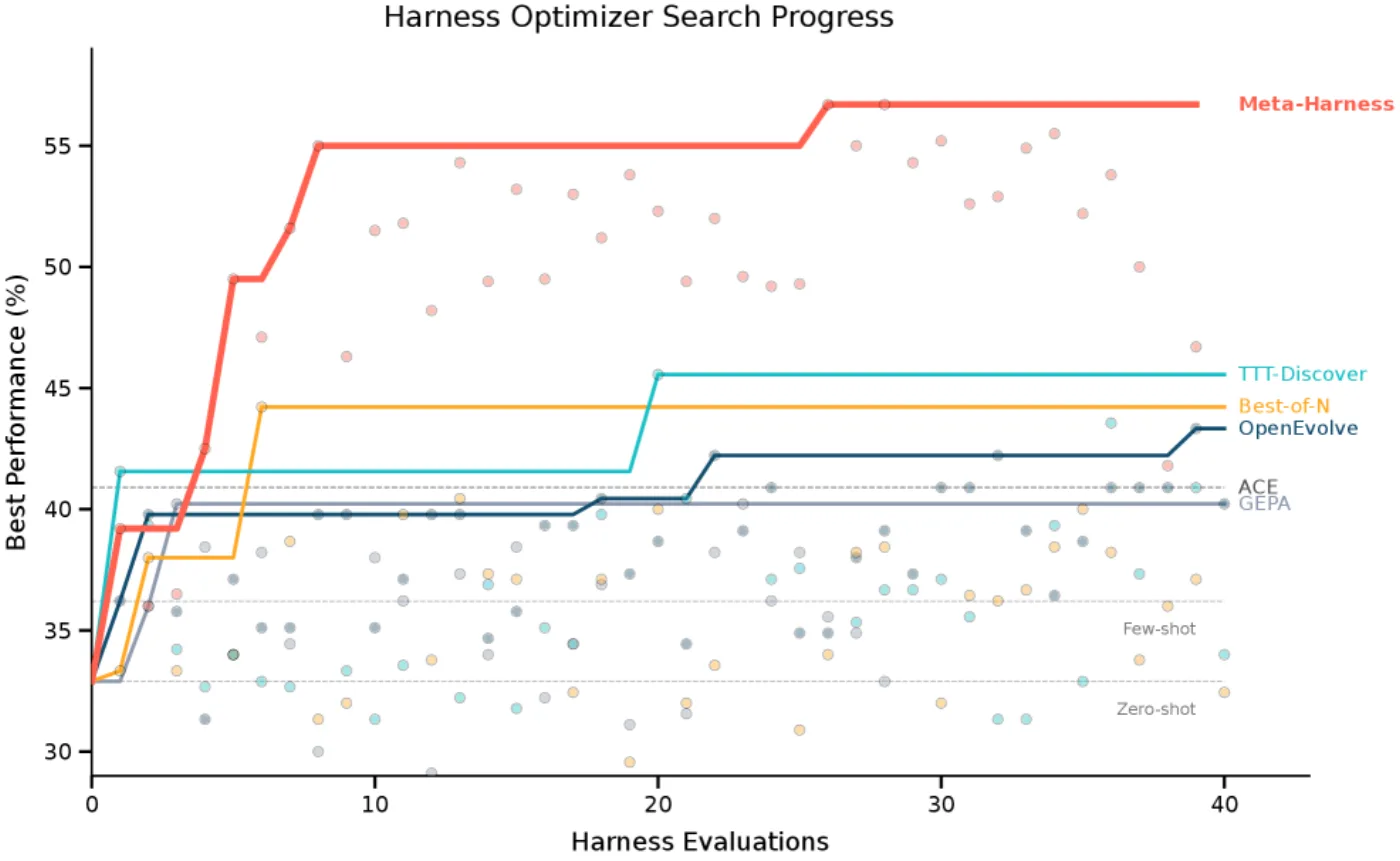
Ограничения (честно)
- Требует больше вычислений на поиск. Нужно несколько десятков попыток. Но если система потом работает месяцами в проде — это окупается.
- Зависит от качества оценки. Если критерий неправильный — система оптимизирует не то. (Эта проблема у всех методов оптимизации.)
- Работает лучше для логически структурированных harness'ей. Если код хаотичный — поиск идёт хуже.
- Новое направление. Боевых production-кейсов пока мало. Это academic-исследование, но воспроизводимое.
Главный вывод
Harness-инженерия — это не «тонкая настройка промптов». Это полноценная инженерная дисциплина, в которой код вокруг модели имеет значение не меньше, чем сама модель.
И главное открытие: если harness можно оптимизировать вручную, его можно оптимизировать и автоматически. Достаточно дать системе полную историю экспериментов и позволить ей рассуждать причинно.
Meta-Harness показывает: это работает. На текстах, на математике, на агентах. За несколько часов поиска система находит варианты, которые люди ищут неделями.
Для новичка в AI: вам не обязательно становиться экспертом по harness-инженерии. Достаточно понимать, что эта дисциплина существует — и что её всё больше будет автоматизировать сам ИИ.